テキストベースの数値データをグラフにplotして視える化するまでの3つの方法
今回次のようなタブ区切りのテキストベースのデータを用いてグラフで視える化するまでに3つの方法を試しましたので紹介します
Id Content 1 33 2 70 3 43 4 60 5 98
なお実行環境はUbuntu16.04ですが、今回紹介する3つの方法はMacOSXやWindowsでも動作すると思います。
1. Python + Pandas + Matplotlib + Jupyter
- Pandas公式HP: http://pandas.pydata.org/
- Matplotlib公式HP: http://matplotlib.org/
- Jupyter公式HP: http://jupyter.org/
コード
import matplotlib.pyplot as plt import pandas as pd # データの読み込み f = open("test.txt", "r") hoge = pd.read_table(f, index_col='Id') f.close() hoge.plot()
出力結果
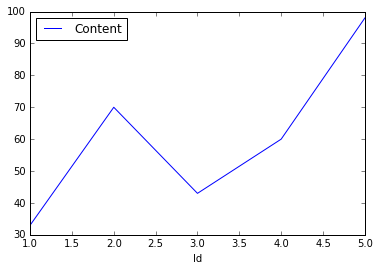
所感
- 実際コードにしてみるとそんなに長くないけど、いろいろ試してうまくいくまでに結構時間がかかった
- 複雑なデータ解析をするときは役にたちそうだけど、軽いデータを取り扱うには重めの環境だと感じた
- もしかしてPandas使わなくてももっと簡単にプロットできたのかもしれない・・・
- Jupyterの保存形式でまるまる作業内容を保存できるのは嬉しい!
2. R + Rstudio
コード
# headerがあるときはheader=Tで認識してくれるらしい x <- read.table("~/Desktop/test.txt", header=T) # type="l"で折れ線グラフで表示させる plot(x, type="l")
出力結果

所感
- に、二行だと!!手軽に自分でデータを確認したいときにピッタリじゃないか!?
- あと細かいデータを確認したいとき、Rstudioのウィンドウを引っ張ってぐいっと引き伸ばすとグラフもぐいっと引き伸ばされるのは個人的に嬉しい機能でした
3. gnuplot
データの前処理
予めヘッダ行をコメントアウトしておきます
# Id Content 1 33 2 70 3 43 4 60 5 98
コード(というかコマンド)
gnuplot plot "test.txt" with line # 画像を保存する場合はこちら(20161209追記) set terminal png # 保存形式を指定 set output 'test.png' # 保存するファイル名を指定 plot "test.txt" with line
出力結果
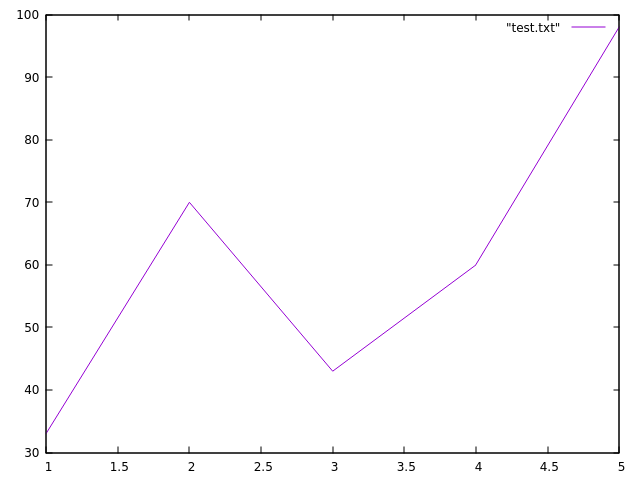
所感
- gnuplot内部のコマンドでもある程度はデータ整形できるけど、いったんlinuxのコマンドで中間ファイル作ってからグラフを描画するほうがやりやすそう?
- Linuxのコマンドと親和性が高いので個人的にテンションあがりました!
まとめ
今回は素早く数値データのプロットをして視える化するのが出口だったので、Rstudioがベストプラクティスでした。
取り組む作業の出口によってベストな解法は変わると思いますので、いろいろなツールをかじっておくといいことがあるかもと思いました。
今日のひとこと
自分で作業していて、なんだかもやもやするときグラフにプロットしてみると以外な発見があるかも!
それではまた!
Vimでなんか知らんが便利なCtrl+r+=で四則演算ができちゃうお話
みなさんこんにちは!今回はvimで四則演算の結果を手軽に貼り付けることのできる機能のお話です。
インサートモード時に
Ctrl+r=11+22
とすると、カーソルの場所に演算の結果"33"がそのまま貼り付けられる素晴らしい機能がVimには標準でついてます。
pythonインタプリタやbcコマンドを使って演算をした後コピペなどが原因で起こるヒューマンエラーをなくすことができるので、とても重宝する機能だと思います。
とっても便利なこの機能、わけもわからず使っていたのですが、、、調べてみたところExpressionレジスタという演算機能を持った特殊なレジスタとのことです。
そもそも、インサートモードの時に Ctrl+r+レジスタ名 でレジスタの中身を利用することができるみたい。
試しに "ayy で任意の行をaキーのレジスタにヤンクしたあとインサートモードで Ctrl+r+a を押してみたら、ヤンクしてきた任意の行がペーストされました。いやーこれは気づけてよかった!超便利!
Pandasとscikit-learnで基本的なクラスタリング分析やってみた
みなさんこんにちは!今回はこちらの記事を参考にPandasの取り扱い方を勉強したので作業メモします!
記事のサンプルコードを一通り通したあとにPandasのデータフレームにして3科目の合計点をカラムに追加したところまでです。
# pandasモジュールの読み込み import pandas as pd
# pandasのオブジェクトにして結合とデータフレームの概要の確認
pd_labels = pd.DataFrame(labels)
pd_features = pd.DataFrame(features)
df.info()
temp_df.info()
# カラムの結合 df_concat = pd.concat([pd_labels, pd_features], axis=1) df_concat
# カラムのヘッダが0,1,2,3という名前になっていたので、df_concat.columnsで一気に名前変更 df_concat.columns = ['Cluster', 'Japanese', 'Math', 'English'] df_concat
# 3科目の点数の合計値を計算して追加 df_concat["sum"] = df_concat[["Japanese","Math", "English"]].sum(axis=1)
次回はこのデータを使ってグラフとか出してみるテストする予定です。
それでは!
オープンソースコミッターになったった!( ・`д・´)
ついに俺もオープンソースコミッターになったったのでご報告だぜー!ヒャッハーウオオオオアアアア( 'ω')/アアアアアッッッッ!!!!!
とあるツールのHow to useの欄にtypoがあったので報告しました。
こちらのツール、バイオインフォマティクス界隈では有名なblastnという塩基配列の相同性を見つけるソフトを高速化させることのできるツールとなっています。
typoの報告がこちら
作者氏> I have corrected the typos. Thanks for reminding!
中西、ついにやりました!!! OSSコミッターになるのが長年の目標だったのでひとまずは目標達成です〜(´ω`)
GithubでのOSS活動にはプルリクというものがあるらしいのでそちらもコードの修正とかも送れるようになるのが次の目標です。
あと流暢な英文が書けるようになるのも目標です。。。
いやー。感謝されるって気持ちのいいものですね!
pyenv globalではpython2をまず設定しましょう
こんばんは!環境構築厨の中西です←
こんな記事をみつけたのでシェア
http://qiita.com/yutaszk/items/4b9e35cd88659ba1ee88qiita.com
brew doctorでpython3のリンクが壊れてるみたいなwarningを吐かれたので調べたら上の記事がHITしました。私の環境では
pyenv global 2.7.11 3.5.1
pythonコマンドとpython2コマンドを2.7.11
python3コマンドを3.5.1に設定しました。自分の意図しないところでpythonが使われる可能性は十分にありえますので、pyenv globalは無難な設定にしておくのがいいのかなーと思いました。
OSX + pyenv + virtualenv + tensorflow で動作確認テストするまでの手順
はじめに
みなさんおはこんばんにちは(# ゚Д゚)
後輩から質問があったので、DeepLearningによく用いられるライブラリの一つであるtensorflowをセットアップして動作確認するまでの手順をまとめてみたいと思います。
今回は、OSX 10.11.6とPython 2.7.10を利用してセッティングしてみたいと思います。
homebrewのインストール
OSXのパッケージマネージャーであるhomebrewを入れます
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
pyenvの設定
homebrewのインストールが終わったらpyenvをインストール
brew install pyenv
pyenvを利用するために以下の設定を.bash_profileに記述しておきます
export PYENV_ROOT=$HOME/.pyenv export PATH=$PYENV_ROOT/bin:$PATH eval "$(pyenv init -)"
設定の再読み込みをさせます
source ~/.bash_profile
そうするとpyenvコマンドがつかえるようになったと思いますので以下のコマンドでpython2.7.10をインストール
pyenv install 2.7.10
OSX上で使うpythonを、pyenvでインストールした2.7.10に切り替えます
pyenv global 2.7.10
virtualenvのインストール
brew install pyenv-virtualenv
virtualenvを利用するために以下の設定を.bash_profileに記述しておきます
eval "$(pyenv virtualenv-init -)"
設定の再読み込み
source ~/.bash_profile
tensorflowのインストール
virtualenv --system-site-packages ~/tensorflow
source ~/tensorflow/bin/activate
export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/mac/tensorflow-0.9.0-py2-none-any.whl
pip install --upgrade $TF_BINARY_URL
ちゃんとインストールできてるか確認
$ python ... >>> import tensorflow as tf >>> hello = tf.constant('Hello, TensorFlow!') >>> sess = tf.Session() >>> print(sess.run(hello)) Hello, TensorFlow! >>> a = tf.constant(10) >>> b = tf.constant(32) >>> print(sess.run(a + b)) 42 >>>
tensorflowでの作業が終わったら以下のコマンドで仮想環境からでます
deactivate
おわりに
ざざっとやらなきゃいけないことだけを書いてきたので、分からないことがあればじゃんじゃん質問よろしくお願いします
Ubuntu16.04でGPUのハードウェア情報を知りたいとき
sudo lshw -class display
以下のページを参考にさせていただきました!
UbuntuTips/Hardware/SearchHardwareInformation - Ubuntu Japanese Wiki